Mitigating Redundant UDF Computations in Spark Plans
When processing big data, efficiency is key. It’s not uncommon to be caught up in long debugging cycles when working with Spark. I was recently caught in such a debugging train when one of my pipelines was taking longer than expected. It was a simple structured streaming pipeline that was listening to a Kafka topic for events and performing some transformations on it, before emitting the output to another Kafka topic. Upon closer inspection, the Spark plan revealed a concerning pattern: the same UDF being invoked multiple times throughout the pipeline when it should have been invoked just once. And sadly, this UDF was a time-taking one.
Reviewing Spark plans is an essential step in the optimization journey of Spark workflows (it can save hours of tormenting debugging). It offers critical insights into how Spark processes data and executes tasks. Identifying performance bottlenecks, understanding the data processing logic, validating optimization strategies and, of course, spotting redundant computations are some of the benefits of habituating the review of Spark plans.
After a long time on the internet (often distracted by HN), I learnt about how Spark treats user-defined functions (UDFs) as deterministic by default. Meaning they yield the same output for a given input every time. While this predictability is generally desirable, it can lead to inefficiencies when Spark re-computes UDFs unnecessarily across the pipeline stages. This redundancy not only impacts performance but also consumes unnecessary computational resources. I found this little piece of information (”evil little piece” perhaps) inside the spark codebase tucked neatly inside a docstring. Here’s an excerpt:
“The user-defined functions are considered deterministic by default. Due to optimization, duplicate invocations may be eliminated or the function may even be invoked more times than it is present in the query. If your function is not deterministic, callasNondeterministic on the user defined function.”
Spark optimizer is responsible for finding the most efficient plan to execute data operations specified in user programs and transform it into a physical execution plan. From what I understood, for certain tasks, Spark could create a plan that could invoke an UDF multiple times rather than just once as intended by the programmer. I’m yet to dig into the internals of Spark to understand why Spark does this (need a lot of coffee ☕ for this). One possible reason, as pointed out by a spark-proficient friend (check out his work, dude’s the Hermoine Granger of tech), could be that Spark might find it to be easier (or faster) to recompute an UDF than bringing the result of that computation from another executor.
So for my immediate problem, I did exactly what the documentation suggested, I called asNondeterministic on the UDF, telling spark to treat this UDF as a nondeterministic UDF. This forces Spark to invoke the UDF once (if that’s what was intended), and avoid redundant calls. Primarily because redundant calls can lead to inconsistencies and side effects.
from pyspark.sql.functions import udf
# Define a deterministic UDF
@udf(returnType=IntegerType())
def double_number(x):
return x * 2
#Mark the UDF as non-deterministic
double_number = double_number.asNondeterministic()
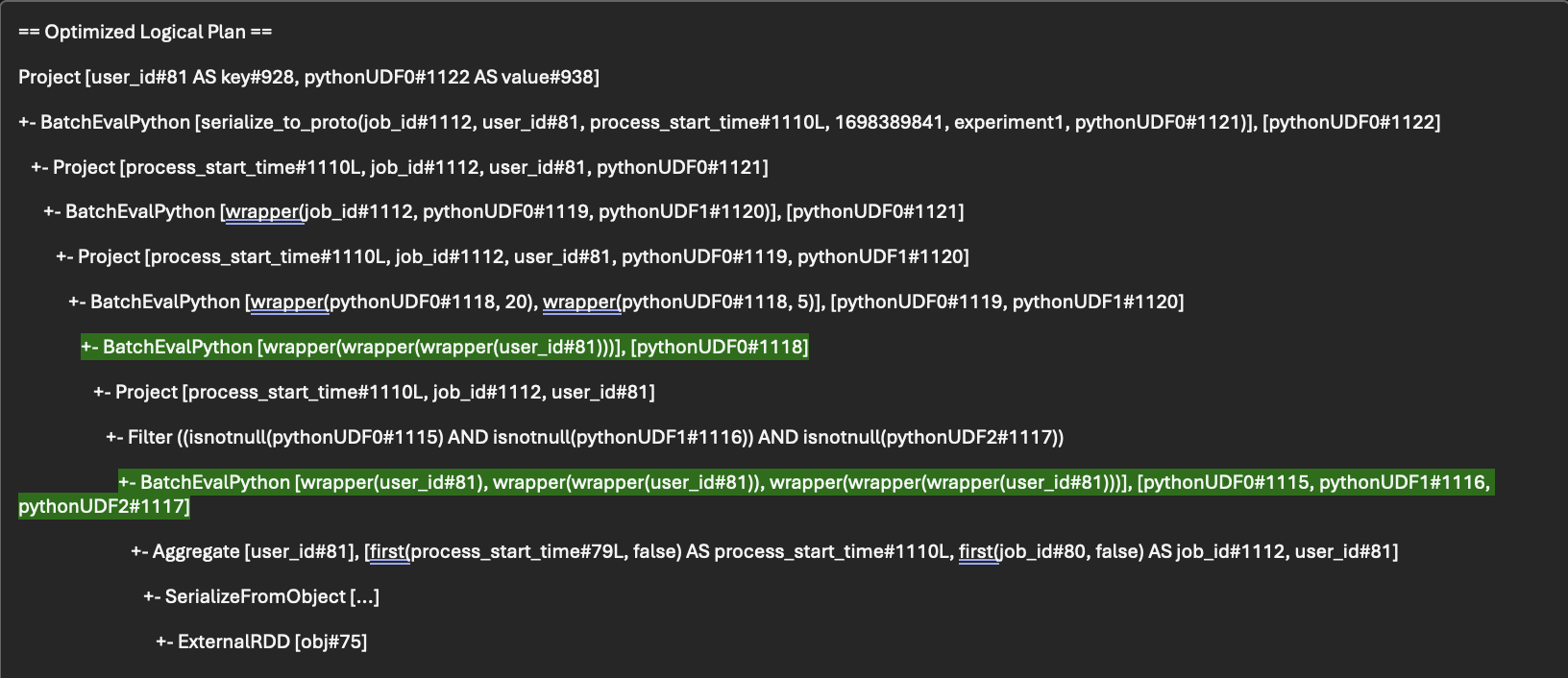
If you look at the Optimized Logical Plan for the task, you can see that wrapper(user_id#81) is invoked multiple times (for pythonUDF#1115, #1116, #1117 & #1118).
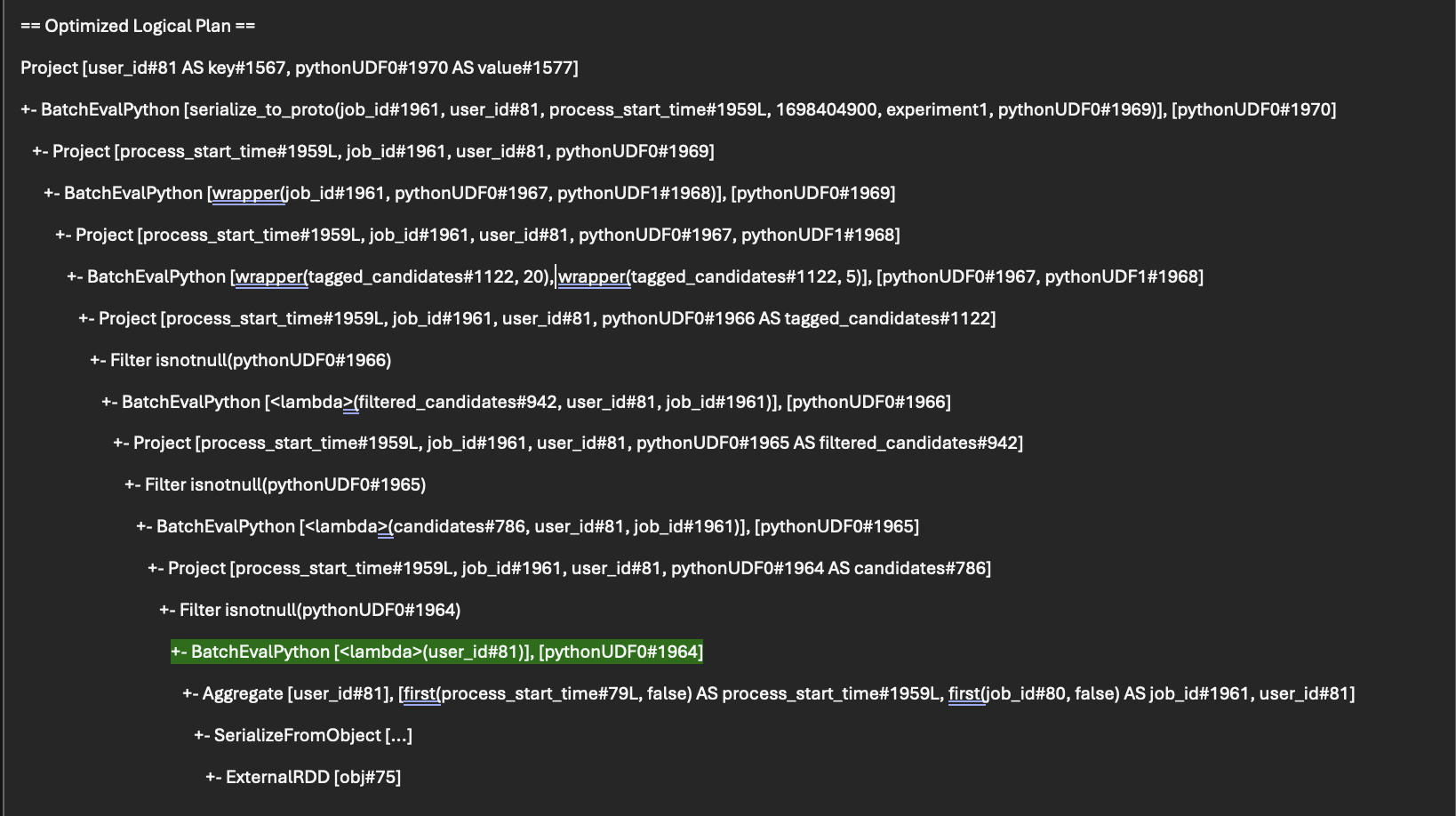
After the change, the Spark plan changed to something more desirable. People were happy that the plan looks much better and I’ve convinced them it was magic.
Alongside UDF optimization, attention should also be paid to optimizing Spark queries and minimizing unnecessary computations. These complementary strategies work in tandem to enhance overall performance and efficiency within Spark workflows. Knowing when to leverage non-deterministic UDFs is crucial for optimizing Spark performance effectively. If your UDFs involve randomness or external state, transitioning to a non-deterministic paradigm can yield substantial improvements in computational efficiency.
However, it’s crucial to approach non-deterministic UDFs with caution. While they can offer tangible benefits in terms of computational efficiency, they also introduce an element of unpredictability. This unpredictability may not be suitable for all use cases, especially those where result consistency is paramount.
On the flip side, using a non-deterministic function as a deterministic UDF also brings in trouble, can’t just go around doing this everywhere. Say that you have a task for which you have to invoke a function that is non-deterministic (it may be a sampler, or involve some form of randomness) multiple times. Spark will treat it as a deterministic UDF by default and maybe invoke it just once in its optimised plan. But we need to call it multiple times since we need that non-deterministic output for our pipeline. So in this case, setting it as non-deterministic UDF is desirable.
Now, for more caution, when considering marking a UDF as non-deterministic (or deterministic) in Apache Spark, it’s crucial to weigh the implications carefully -
- Impact on Result Consistency: As briefed earlier, it introduces randomness or variability into the computation process. Ensure that the potential variation aligns with your use case and doesn’t compromise result consistency.
- Consideration of Data Stability: If your data is expected to remain stable between Spark job runs, using non-deterministic UDFs may introduce unnecessary fluctuations in results. Evaluate whether the potential benefits of non-determinism outweigh the risks of data instability in your specific scenario.
- Performance Overhead: While non-deterministic UDFs can optimize Spark plans by reducing redundant computations, they may also introduce additional overhead due to the need for repeated evaluation if repeated invocations are part of your pipeline. Consider the trade-off between performance gains and the computational cost of non-deterministic UDFs.
- Effect on Caching and Reproducibility: Non-deterministic UDFs can impact caching strategies and result reproducibility. Cached results may not be consistent across different runs if non-deterministic UDFs are involved. Ensure that your caching strategy aligns with the behavior of non-deterministic UDFs to avoid unexpected results.
- Testing and Validation: Introducing non-deterministic elements into your Spark workflows requires thorough testing and validation. Verify that the variability introduced by non-deterministic UDFs does not adversely affect downstream processes or analysis results. Consider running multiple iterations of your Spark job to assess the stability and reliability of the outcomes.
- Documentation and Communication: Clearly document the usage of non-deterministic UDFs in your Spark codebase and communicate their implications to other team members or stakeholders. Provide context on why certain UDFs are marked as non-deterministic and any considerations or constraints associated with their usage.
- Cherry Pick Non-Determinism: This is primarily beneficial only when the UDFs are complex and takes significant amount of time. If they are simple UDFs that execute fast, then this optimisation may not necessarily improve your runtime.
By keeping these considerations in mind, you can make informed decisions about when and how to leverage non-deterministic UDFs in Apache Spark, balancing performance optimization with result consistency and reliability.